インフラ障害対応訓練会
概要
インフラ周りで障害が起きたことを想定した訓練を行う
様々なメトリクスを確認して障害対応の流れを確認し、メンバーの障害対応スキルを上げる
過去の障害対応をリプレイ
議事録
障害対応のはじまり
- #bug_lips_danger
- PagerDutyでアラートが飛んだりして対応している
- 要対応でやばめのやつ。基本的にバトル開始する
- 大事なやつが上に貼ってある
- https://ap-northeast-1.console.aws.amazon.com/cloudwatch/home?region=ap-northeast-1#dashboards:name=lips-danger-view
- ダッシュボードを見てどこがまずそうかを確認していく
- 今日はここの流れをやっていく
- 最近はアラートに気がついたら、huddleに集まって相談しつつ進めるルールになっている
- 分からなかったら人を集めるのも大事なので呼びかけていく
- デプロイ起因のときはPR関係者とかを呼ぶなど
- デプロイ完了した結果が流れてくるチャンネル #dev_make_server_deploy_notify を見るとよい
- 必要に応じてSNSへのアナウンス・他チームへの連携などをやる

- #bug_lips_warning
- dangerより厳しめに設定されているアラートが飛んでくる
- #bug_make_server
- bugsnagに飛んでるエラーが流れる
- #bug_report
- バグが起きていたら報告などをする
過去の障害の振り返り
問題解消・原因究明の流れ
- メトリクス・エラーログ等の怪しそうなところを順番に見ていく
- よくある原因と対処法
- 直近頻繁にはメンテされていないが典型的で重要なことが書いてあるので参考にすると良い
- とりあえずrollback、再起動でなるはやに治せることが結構ある
- 対症療法的にでも良いので、ユーザーから見て最速で復旧することを目指す
- その後、原因を詳細に分析したり、影響を調査したり、再発防止策を考えたりして振り返りにまとめる
ダッシュボードの見方
ロードバランサーのレスポンスタイム

ユーザーから見てどれくらいレスポンスに時間がかかっているか
ユーザーから見て遅いときはだいたいここが跳ねている
Aurora

RDSはクラスタになっていて、それぞれのインスタンス別に表示されている
RDSが怪しいときはRDSのページで詳細なメトリクスが見られる
LIPSの障害だいたいRDSがち
重いクエリが来てCPUがさちりがち
CPUが赤くなっていると怪しい
設定についてはここにまとまっている(ちょっと古い)
重いクエリが分かったら
とりあえずrollbackして問題のクエリを発行していそうなところを直す
サチったまま張り付いているときはreboot
rebootすると 1~5 分程度のダウンタイムが発生するが、それによるユーザーの体験がどうか次第でrebootすべきかどうか決める。たとえば10分くらい使えないならしちゃったほうが良い
データの不整合とかもありえるが、そこまでちゃんときにせずにやってよい(ユーザーの体験のほうが大事)
ユーザーから見て使えている場合は要検討
クラスタになっているので増やせる
パワーを上げる or 台数を増やす
Add readerでread replicaを増やせる
custom endpointを使っているので、増やすだけだとちゃんとつながらないことに注意。書き換える必要がある
ログ
エラーログとスロークエリログがある。よく分からなかったら見ると良い
構造化されたログ等(splunk等?)は現状は存在しない
コツ
ダウンロードして見ると良い
デッドロックのログは難しい 👶
ECS

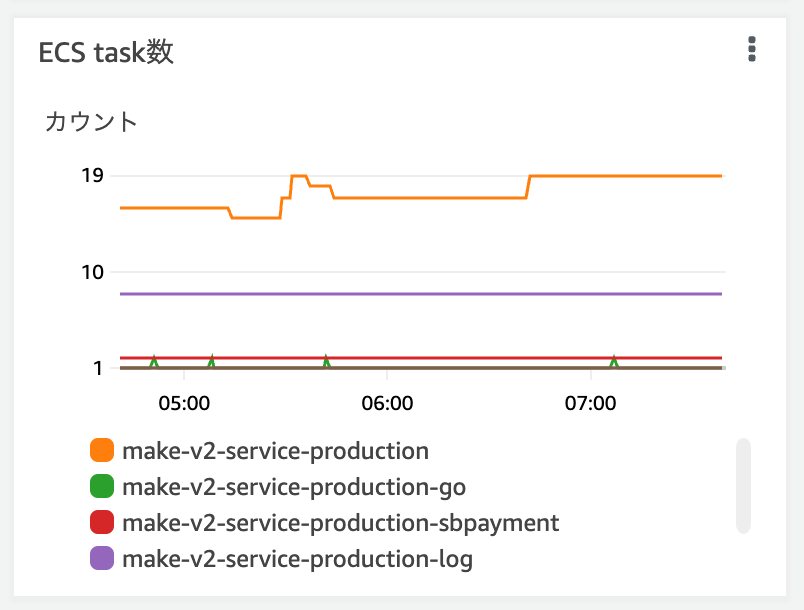
ECSはEC2を束ねて名前をつけて管理してくれるやつ
インスタンス増減したときの繋ぎ変えや負荷分散など。コンテナをいい感じに動かす
まとまっているものをクラスタと呼ぶ
https://ap-northeast-1.console.aws.amazon.com/ecs/home?region=ap-northeast-1#/clusters
make-v2-production
Deploymentタブでデプロイの状況が見られる
Eventsタブで何が起きたかログが見られたりする
よくある問題
AutoScaling の Desired countとRunning countがずれていること
負荷が高くなると台数を増やしてくれるクン
LIPSは朝と夜で結構違ったりするので、だんだんtaskの数を増やしたり減らしたりしている
ヘルスチェック失敗問題
最近少ない
ECSはコンテナが落ちたり不健全な感じになったときにサービスを維持するために頑張ってくれるが、うまくいかないこともある。そのときにヘルスチェックで問題が起きる
結構な数のタスクがまとめて突然死すると負荷が集中して障害となることがまれにある
Eventsに死んだログがたくさん流れているとそうなることが多い
ほっとくとそのうち戻ることもしばしば
急いで戻したければ手動でDesired countを増やしたり、インスタンスのデプロイを走らせたりすると早く解消することもある
右上のUpdateからForce new deploymentにチェックを入れて強制デプロイできる
徐々に入れ替わっていくだけなので気軽にやってOK
Auto Scalingにより、Desired countは勝手に減ってくれる
手動で増やしても負荷によって減っていってくれるので再設定とかは不要
マイナーなServiceではAuto Scalingが設定されていないかもれないため注意
プッシュ通知とかのために事前に増やしても戻ってしまう?
scale inは5分に1回1タスクとかのペースなので、多めに増やしておけば大丈夫
Auto Scalingで最小タスク数が設定できるのでそこをいじるのも良さそう
ElasticSearch
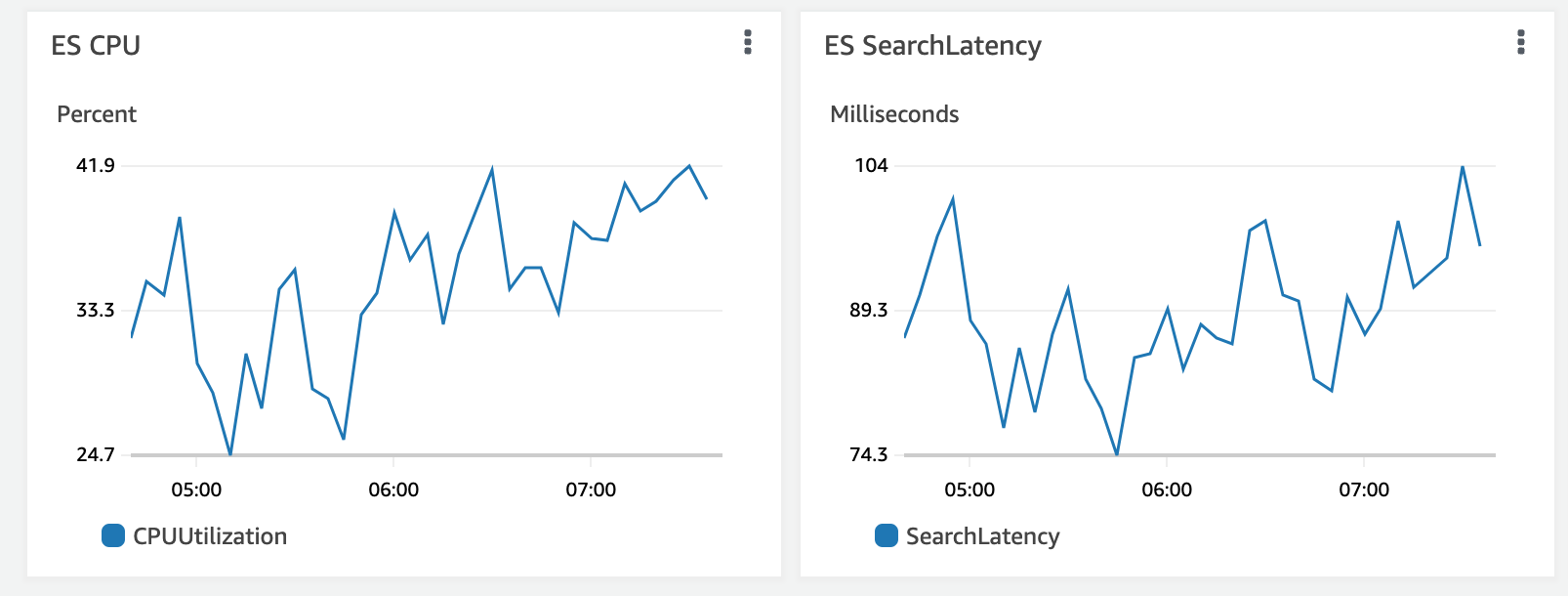
production-lipsが本番環境で使われているもの
Search Latency でユーザー絡みて検索が遅いか分かる
データノードがサチっていることが多い
検索スレッドプールを見るとリクエストをさばききれなくなっている状況がわかる
問題があったときは増やしたりしていく
ElasticSearchも分散している
マスターノード3台とデータノード6台で構成されている
データノードのCPUがサチっていたら台数を増やす
クラスター設定の編集から台数を増やしたりインスタンスタイプを変えたりできる
データノードを増やすだけでは負荷分散されないので注意が必要
replicaを増やす必要があり、その話が上記マニュアルに記載されている
ログとはあんまり見ない(役立たないがち)
スローログ見ると原因究明に役立つことはあるが大体Postなのであまり役には立たない
ElasticSearch側にステータスを返してくれるendpointがあってそっちを見ることはある